Transformation im Automobilsektor durch KI
In diesem Artikel möchte ich auf die Umwälzungen eingehen, die sich gerade in der Industrie abzeichnen, mit besonderem Fokus auf die Automobilbranche. Zwei große Trends kommen hier zusammen: die Ausbreitung der KI und der gesellschaftliche Wandel. Und zwar auf Seiten der Industrie wie auch auf Seiten der Kunden.
- Motivation – KI und Transformation?
- Transformation im Automotive Sektor
- KI im Automotive R&D Bereich
- KI im Fahrzeug
- Deep Driving
- Herausforderung: Absicherung und Test
- Herausforderung: Spezielle Attacken
- KI für das Software-Engineering
- KI im Fahrzeug
- KI für sicherheitsrelevante Systeme?
- Einordnung
Motivation – KI und Transformation?
Unsere Volkswirtschaftliche Situation
Die volkswirtschaftliche Situation in Deutschland und vielen anderen westlichen Ländern spitzt sich zunehmend zu: der demographische Wandel sorgt dafür, dass wir zunehmend weniger Arbeitskräfte haben pro Einwohner. Warum ist „pro Einwohner“ wichtig? Wenn die Bevölkerung zurückgehen würde, würde auch die Nachfrage nach Produkten und Dienstleistungen zurückgehen. Bei uns bleibt die Bevölkerung jedoch relativ konstant, und damit der Bedarf. Genaugenommen steigt der Bedarf sogar in vielen Bereichen wie z.B. der medizinischen Versorgung und der Pflege.

Das heißt: das, was ein Arbeitnehmer erwirtschaftet muss ausreichen, um immer mehr Menschen zu versorgen.
Zunahme oder Abnahme der Produktivität?
Schauen wir nun, wie es sich mit der Produktivität verhält. In Deutschland steigt die Produktivität pro gearbeitete stunde recht stetig. Gleichzeitig nimmt aber die Anzahl der gearbeiteten Stunden pro Person schon seit 2012 stetig ab. Zusammengenommen gleicht es sich aus, die Gesamtproduktivität pro Person bleibt etwas gleich.
Aufgrund des demographischen Wandels müsste die Gesamtproduktivität pro Person aber steigen!
In den USA sieht es anders aus: hier bleiben die gearbeiteten Stunden pro Person relativ konstant, somit steigt die Gesamtproduktivität pro Person.

KI zur Steigerung der Produktivität
Als die Wirtschaft im Bereich der Fertigung unter Druck geraten ist, wurde darauf mit Automatisierung und Rationalisierung reagiert. Die gleichen Maßnahmen müssen wir auch jetzt ergreifen, nur nicht mehr auf die Fertigung beschränkt. Die Arbeiten, die durch eine KI erledigt werden können, sollten durch die KI erledigt werden, so, dass die Menschen sich auf die Arbeiten konzentrieren können, die von Menschen gemacht werden, muss. Es gibt auch Aufgaben, bei denen der Menschen besser ist und es gibt Aufgaben, bei denen ist die KI besser als der Mensch, z.B. bei der Beherrschung großer Datenmengen oder hochkomplexer Systeme.
Außerdem ist die KI oft viel schneller als ein Mensch. Das heißt, selbst in aufgaben, in denen der Mensch besser ist, kann eine KI zur Effizienzsteigerung beitragen, wenn sie erste grobe Arbeitsergebnisse oder Bausteine erstellt, die der Mensch danach verfeinert.
KI entwickelt sich weiter
Auch muss man berücksichtigen, dass sich die KI immer weiter entwickelt. Eine Aufgabe, die heute noch nicht möglich ist, wird nächstes Jahr vielleicht schon möglich sein. Wir müssen hierbei immer „am Ball bleiben“.
Und die Entwicklung wird immer schneller: die technologische Entwicklung ist eine Exponentialfunktion. Schon Moore’s Law stellte dies fest und besagt sinngemäß „Die Rechenkapazität von uC verdoppelt sich alle 12-24 Monate“, was eine quadratische Steigung ist. Die Rechenkapazität ist für KI von zentraler Bedeutung, weil besonders im Deep Learning enorme Datenmengen verarbeitet werden müssen.
Ein kleiner Exkurs an einem Beispiel: was ist exponentielles Wachstum.
Ein mehr praktisches Beispiel, wie sich Technologie entwickelt ist sehr schön hier zusammengefasst von Bost Dynamics, denen ich seit Jahrzehnten begeistert verfolge:
Sollten wir KI (streng) regulieren?
KI ist ein mächtiges Werkzeug, und sie wird immer mächtiger, die Entwicklung geht immer weiter. Da ist es naheliegend zu fragen, ob wir die KI nicht streng regulieren sollten.
Das Problem: Regulierung von KI ist ein Prisoners‘ Dilemma
Transformation im Automotive Sektor
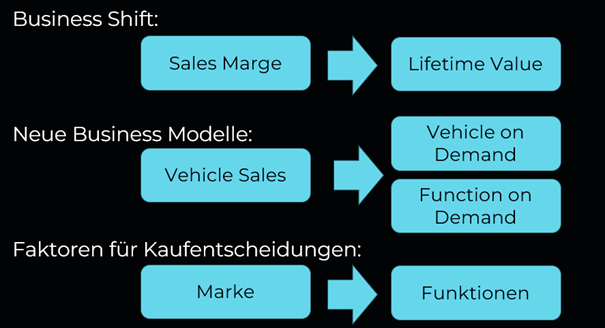
Im Automotive Sektor sehen wir eine komplette Verschiebung der Geschäftsmodelle
Früher stand für die Automobilhersteller die Marge beim Verkauf und das Geschäft mit Ersatzteilen im Vordergrund. Der Kampf um die Marge war die zentrale Kennzahl. Das verschiebt sich zur Zeit in Richtung „Lifetime Value“. Das heißt, welche Geschäfte kann ich mit dem Fahrzeug nach dem Verkauf machen? Zunehmend kann man Software-Funktionen und Assistenzsysteme noch nachkaufen. Zukünftig wird sich dieses Modell in Richtung Pay-per-Use weiterentwickeln.

Auch die Faktoren für eine Kaufentscheidung verschieben sich stark. Früher war die Marke und das Image verkaufsentscheidend. Für den Alltag des Durchschnittskunden waren alle Fahrzeuge „gleich genug“. Mit den zunehmenden Funktionen im Fahrzeug, werden diese aber immer wichtiger. Vielfahrer schätzen ein Adaptiv Cruise Control, Eltern ein Entertainment-Paket für die Kinder.
Entwicklungszyklus eines Fahrzeuges wird kürzer
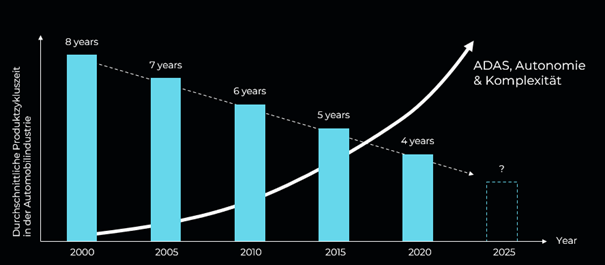
Gleichzeitig mit der Zunahme der Funktionen erwarten die Kunden, Neuerungen immer schneller zu bekommen. Acht Jahre gelten heute als eine Ewigkeit.
Als ich im Automotive-Bereich angefangen habe, waren acht Jahre der Entwicklungs- und Produktionszyklus eines Fahrzeugs. Das heißt, ein Fahrzeug wurde entwickelt und dann bis zu acht Jahre lang gebaut, dann kommt das Nachfolgermodell auf den Markt.
Dann wurden die „Face Lift“ nach vier Jahren eingeschoben, was ein erhebliches Update, aber kein Neudesign war.
Und auch hier geht es immer schneller. Vor allem aus dem chinesischen Markt kommt ein erheblicher Beschleunigungsdruck.
Herausforderungen aus Komplexität und Beschleunigung
Der traditionelle (Software) Entwicklungszyklus funktioniert nicht mehr
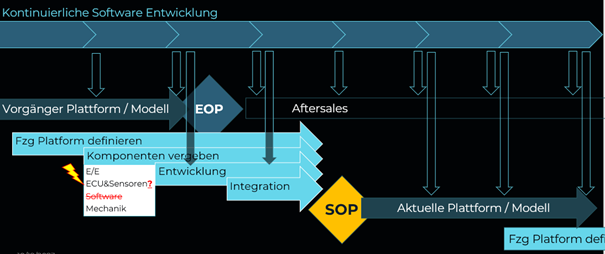
Bisher war der Software Entwicklungszyklus and den des Gesamtfahrzeugs angepasst. Im „Sourcing“ wurde Software bzw. Funktionen zusammen mit ECUs, Sensoren und der übrigen Hardware „vergeben“.
Da Funktions-Update immer schneller nötig sind und auch Updates für Fahrzeuge im Aftersales bereitgestellt werden müssen, macht es keinen Sinn mehr einen Software-Entwicklungs-Strang an den Modell Zyklus oder an ein Modell zu koppeln. Stattdessen etabliert sich ein durchgehender Entwicklungsstrang, der mehrere Modelle bedient, und sowohl im Aftersales, im Sales und in der Entwicklung.
Problem: Abstraktion von Software und Hardware
Ein Problem, was hierbei entsteht ist, dass Automotive Software traditionell sehr stark an der Hardware orientiert gewesen ist. Grund war, dass die Hardware so günstig wie möglich gehalten werden sollte und die Software die Hardware möglichst perfekt ausreizen sollte. Wenn man eine Million stück eines Fahrzeugs verkauft und bei einem Sensor nur 1 Euro spart, ist das in Summe eine Menge Geld.
Diese Logik wird aufgebrochen. Sensoren und ECUs müssen zunehmen Reserven für Updates vorhalten. Zurzeit sind 10% – 20% nicht unüblich. Aber auch an die Software stellen sich neue Herausforderungen, wenn eine Software mit bis zu 10 oder gar 20 Jahre alten und gleichzeitig mit zukünftigen Sensoren funktionieren soll. Das gleiche trifft auf die gesamte E/E Architektur, vor allem den Fahrzeugbus, zu. Auch Sensoren werden ausgetauscht werden müssen.
Problem: von der Re-Simulation zur Simulation
Traditionell wurden Fahrerassistenzsysteme in der sog. Re-Simulation abgesichert. Das heißt, dass eine Flotte von Testfahrzeugen einige hunderttausend bis Millionen Kilometer Sensordaten etwa von Kamera und Radar aufzeichnet. Und dann wird jede Funktion vor dem Release mit diesen Daten getestet, wobei festgelegte Kennzahlen einzuhalten sind. Z.B. dass ein Emergency Brake Assist nur eine Fehlbremsung pro hunderttausend Kilometer auslöst. Nach jeder Software-Änderung wird dann erneut getestet. Der Aufwand hierfür ging schon mit den Level 2 System in den kritischen Bereich, da die Kennzahlen immer strenger und die Szenarien immer herausfordernder werden (siehe z.B. Euro NCAP 2025).
Mit Funktionen, die aktive Lenkeingriffe vornehmen, funktioniert dies nicht mehr, da schon eine Sekunde nach einem Lenkeingriff die aufgezeichneten Daten von der Situation abweichen, weil das Test-Fahrzeug den Lenkeingriff nicht durchgeführt hat. Hierfür werden nun möglichst realitätsnahe Simulationen benötigt. Diese müssen aber natürlich wieder gegen die reale Welt getestet werden, um nachzuweisen, dass sie realitätsnah genug sind.
Aber keine Simulation kann gut genug sein, denn wir können nur Situationen oder „Umstände“ simulieren, die uns bewusst sind. Der Grund für die großen Mengen an Testkilometern war die Argumentation, dass man bei einer Million km schon alle Corner Cases mindestens ein Mal aufgezeichnet haben wird.
Und für die Sensoren und die Wahrnehmungs-Software ist eine Simulation besonders schwierig, weil die Simulationen selten bis auf tiefste Level physikalisch korrekt sind. Vor allem bei Sensoren, die mit Wellenausbreitung arbeiten wie z.B. Radar.
Das Resultat ist, dass wir es mit einer komplexen Mischung aus Simulation und Re-Simulation zu tun bekommen, um die Absicherung der Funktionen sicherzustellen.
KI im Automotive R&D Bereich
Im Automotive Bereich müssen wir zunächst zwei Gebiete trennen: KI im Fahrzeug als Teil des Produktes und KI als Werkzeug zur Entwicklung.

KI im Fahrzeug
Hier haben wir wiederum zwei große Themenblöcke: KI zur Fahrzeugsteuerung und KI im HMI und Infotainment.
Für beides möchte ich einen kurzen Impuls setzen.
KI im HMI / Infotainment
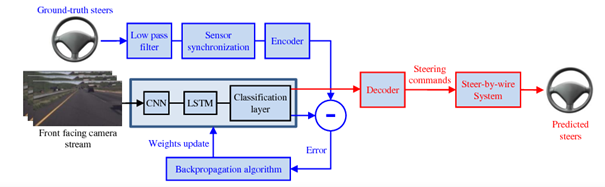
Die aktuellen Entwicklungen im Bereich LLM, Chatbots, Dialogsysteme, Spracherkennung, Sprachgenerierung ermöglichen es, virtuelle Avatare zu erzeugen mit denen der Anwender über ein Fachliches Thema sprechen kann.
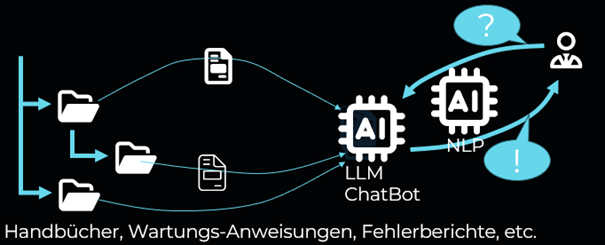
Dies ist optimal für das Infotainment im Fahrzeug, vor allem für den Fahrer. Wer kennt das nicht: im Armaturenbrett leuchtet plötzlich ein Warn-Icon auf. Doch was bedeutet das? Während der Fahrt kann man unmöglich das Handbuch aufschlagen. Und auch wenn man auf dem nächsten Rastplatz rausfährt stellt man oft fest, dass das Bord-Handbuch nur sehr grob weiter hilft.

Mit den heute verfügbaren Mitteln kann der Hersteller ein Index-Modell trainieren mit den für das Fahrzeug relevanten Dokumenten. Zusammen mit dem Index kann ein LLM dann ein Chat-Bot bilden. Es gibt hierfür bereits zahlreiche Applikationen im Web. Z.B. Lyris hat eine Free Trial Version zum ausprobieren oder für mehr experimentierfreudige Llama Index. Sogar die Fehlerberichte und Wartungsprotokolle des konkreten Fahrzeugs könnte man integrieren. In Verbindung mit Spracherkennung und Sprachsynthetisierung kann dann der Fahrer mit dem Chatbot sprechen.
Etwas mehr zu Indexmodellen hier.
KI zur Steuerung des Fahrzeugs – Deep Driving
Deep Driving hat zu einer kleinen Revolution geführt: es hat das Entwickeln von hochautomatisiertem Fahren stark vereinfacht. Dieser Trend geht seit etwas 2015. Davor waren auf der DARPA Grand Challenge und Urban Challenge Teams angetreten, die hochspezialisierte, hochkomplexe Algorithmen entwickelt hatten. NVIDIA Drive hat das deutlich vereinfach.
Heute kann mit entsprechenden Trainings-Frameworks und offenen Datensets im Prinzip jeder ein automatisiertes Fahrzeug zum Fahren bringen.
Und hier ein beispielhaftes Video, was ein entsprechend fahrendes System zeigt.
Herausforderung: Absicherung und Test
Eine große Frage ist die Zulassungen solcher Systeme. Klassischerweise gibt es Prozess- und Test-Anforderungen für sicherheitskritische Systeme, etwas aus der ISO26262. Diese müssen eingehalten und nachgewiesen werden für eine Zulassung.
Typischerweise fordern diese, dass die Designten Systeme und Codes gründlich gereviewt sind und dass alle Software Module nach speziellen Anforderungen getestet wurden, um deren fehlerfreie Operation sicherzustellen.
All dies funktioniert mit Deep Driving Modellen so nicht mehr. Es gibt kein funktionales Design, was man reviewen kann und es gibt keine einzelnen Module mehr in einer Form, für die man Testfälle spezifizieren kann.
Auch für menschliche Reviewer ist es u.U. nicht mehr zu verstehen, was das Neuronale Netz gelernt hat. Es gibt viele Forschungsansätze das erklärbar zu machen oder zu visualisieren, aber die sind von einem industriellen Einsatz noch ein stück entfernt. Und auch mit einer Visualisierung ist es noch nicht erledigt, dann folgt die Interpretation, die ist mindestens genauso schwierig.
Hier ein Beispiel von Alex Net, ein Beitrag zur ImageNet Large Scale Visual Recognition Challenge, wie die Visualisierung der einzelnen Layers der CNN (Convolution Neural Networks) aussehen kann:

Herausforderung: Spezielle Attacken
Da, wo sich neue Systeme und Architekturen etablieren, entstehen auch neue Schwachstellen. So auch bei Deep Neural Networks: die Adversarial Attacks. Hierbei geht es um die Erzeugung von speziellen Daten, z.B. Bildern, die beim Neuronalen Netz zu einer Fehlklassifikation führen. Diese Daten werden so erzeugt, dass sie für einen menschlichen Betrachter nicht erkennbar sind oder harmlos erscheinen. Zunächst wurden Bilder mit scheinbarem Rauschen verändert, aber es gibt auch schon Angriffe in denen die reale Umwelt durch einzelne Aufkleber so verändert werden kann, dass ein Neuronales Netz etwas Verkehrszeichen falsch klassifiziert.


Auch in diesem Artikel und Paper von K.Eykholt et al sind einige weiterführende Beispiele und Erklärungen enthalten, u.A. konnte ein Tesla zu einem Spurwechsel gebracht werden.
KI für das Software-Engineering
Software Engineering ist viel mehr „Papierarbeit“, als man sich das vorstellen würde. Ein verbreitetes Modell ist das bekannte V-Modell, es hat direkt oder indirekt, Einzug in viele Normen und Standards gefunden: über all dort, wo die Basis Anforderungs- und Anforderungs-Test basiertes Entwickeln und Absichern ist. „Programmiert“ wird hierbei nur an der Spitze des „V“.

{kind=link}
Vor allem in den oberen Schritten haben wir es mit „Requirements Engineering“ bzw. „Anforderungsmanagement“ zu tun. Der Auftraggeber schreibt hier meist natürlichsprachig die Anforderungen – nicht selten tausende, der Auftragnehmer bewertet sie, verknüpft sie mit eigenen internen Anforderungen und antwortet dem Auftraggeber. Folgend darauf werden die Anforderungen verfeinert, daher heruntergebrochen auf kleiner Funktionalitäten. Daraus werden dann schrittweise Architekturen erstellt, die ihrerseits verfeinert werden.
Hier ist ein erster Ansatzpunkt für die Large Language Models, weil sie prädestiniert für natürlichsprachige Arbeit sind.
Eine Möglichkeit ist der Einsatz von LLM bereits das Schreiben der Anforderungen. Die Anforderungen ergeben sich meist aus bereits existierenden Dokumenten. Ein Indexmodell kann mit diesen internen Dokumenten trainiert werden und zusammen mit einem LLM können dann Anforderungen erzeugt werden. Es gibt bereits ähnliche Ansätze z.B. im Wissens-Management, wo zum Training von Mitarbeitern automatisch Quizze erstellt werden. Hier würden die atomaren Aussagen dann nicht als Quizfrage behandelt, sondern als Anforderung formuliert. Der zugrundeliegende Mechanismus ist derselbe.
Etwas mehr zu Indexmodellen hier.
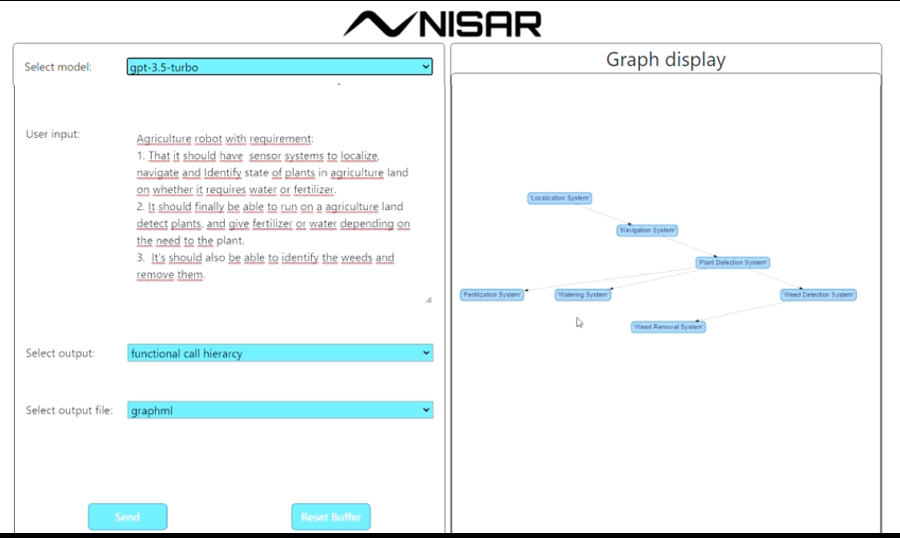
Bei Nisar arbeiten wir am nächsten Schritt, aus Anforderungen Architekturen zu erzeugen und diese dann halbautomatisch zu verfeinern, über die Function Call Hierarchy, die schon sehr Coding-Nah ist bis hin zum Code selbst.

Auch im Code schreiben sind die LLM schon sehr weit – was nicht verwunderlich ist: Code ist auch Sprache. Also ist es naheliegend, dass hier erhebliche Fähigkeiten liegen.
Es wurde schon mehrfach gezeigt, dass LLM z.B. Webseiten und Smartphone Apps schreiben können und auch, dass sie selbstständig Fehler korrigieren können, woraus Ansätze wie AutoGPT entstehen.
Eins der mittlerweile unzähligen Beispiele, wie GPT zum Programmieren eingesetzt werden kann:
KI auch für sicherheitsrelevante Systeme?
Im automotive Bereich haben wir es mit sicherheitskritischen Systemen zu tun. Wir kann man KI hier einsetzen?
Einen Ansatz sehe ich indem man die KI so interpretiert, als wäre sie ein Junior Mitarbeiter. Auch Menschen machen Fehler. Die KI soll hier nicht absolute Korrektheit liefern, sondern menschenähnliche Korrektheit – nur viel schneller. Die Fehler müssen in den üblichen Review- und Test-Prozessen gefunden werden.
Ein anderer Ansatz, den wir bei Nisar zusammen mit CARISSMA der TH Ingolstadt verfolgen ist es, logik-basierte und generative KI zu kombinieren. Logik-basierte KI, z.B. Ontologien sind vollständig beschreibbar, transparent und validierbar. Eine solche KI könnte die Regeln vorgeben, nach der eine generative KI danach Anforderungen oder code generiert und diese Regeln würden auch gleich als Testkriterien gelten, um die Ergebnisse zu prüfen.
Siehe unser Beitrag zu dem Thema bei der BAY.AI.

Einordnung
Ich verstehe KI als „fleißigen Junior“, der versteht manchmal was falsch, macht mal Fehler. Ist aber 24/7 verfügbar, skaliert nahezu beliebig, erledigt Aufgaben in Minuten.
Wir haben damit die Chance, die Produktivität zu erhalten trotz sinkender Arbeitsstunden pro Person- die Arbeit wird dann zunehmen von der KI übernommen. Die Fachleute können sich auf Kern-Aufgaben konzentrieren.
Hieraus ergeben sich einige gesellschaftliche Fragen:
- LLM lernen von Kreativen und Fachleuten und monetarisieren deren Know-How – wie kann man diese daran beteiligen?
- „LLM als Junior“
- Wenn man aber unbegrenzt Juniors hat, wer stellt dann Juniors ein, die später zu Seniors werden?
- Wie lernen Juniors, wenn auch sie selbst nur die LLM bedienen, weil es effizienter ist? Der Mensch lernt durch „machen“ – und Fehler machen…
Abschließen möchte ich mit einem Zitat:
“Wenn ich die Leute gefragt hätte, was sie wollen, hätten sie gesagt: schnellere Pferde.”
Henry Ford (zugeschrieben)
No responses yet